Par Xavier Ciana, Emmanuel Ducry et Anouk Dunant Gonzenbach
Voici le second billet consacré aux métadonnées intégrées aux images numérisées. Après un précédent panorama des principaux standards de métadonnées, celui-ci présente les choix effectués par deux institutions publiques genevoises en matière de métadonnées images.
Dans le cadre de la diffusion d’archives numérisées (de documents anciens dont les originaux sont conservés), les deux objectifs principaux qui motivent l’intégration de métadonnées dans des images sont d’identifier la provenance des documents et d’informer sur les conditions d’utilisation.
L’identification ne pose pas de problèmes lorsqu’un document numérisé est consulté dans son contexte, en général sur le site web de l’institution qui l’a numérisé. Par exemple, lorsqu’un registre d’état civil est consulté sur le site d’une collectivité publique, l’interface de consultation servant d’outil de recherche fournit les informations nécessaire à l’identification du registre original ainsi que les éléments de contexte nécessaires à sa compréhension (provenance, date, etc.).
Mais que se passe-t-il lorsqu’un document – ou une partie de celui-ci – est extrait de son contexte puis republié? C’est un axiome du monde numérique : tout document qui peut être lu peut être copié et reproduit. En général, plus un document suscite de l’intérêt, plus il est reproduit et partagé. Et plus les copies sont nombreuses, plus la probabilité est forte que les informations qui accompagnaient le document lors de la publication initiale soient laissées de côté. C’est ici que les métadonnées intégrées jouent un rôle : lorsqu’une personne copie une image avec des métadonnées, elle reproduit également, même sans le savoir, des informations sur cette image.
Les métadonnées intégrées permettent donc de signaler l’institution qui a numérisé une image ainsi que d’identifier cette image sans ambiguïté (grâce à une cote ou un identifiant unique). Sans informations d’accompagnement ni métadonnées intégrées, il peut être extrêmement difficile de retrouver le fonds ou le dossier d’origine d’une image isolée.
Le choix des métadonnées liées aux conditions d’utilisation feront l’objet d’un prochain billet.
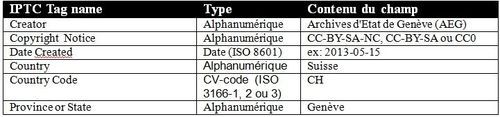
- Métadonnées images retenues par les archives d’Etat de Genève
Le choix de départ s’est évidemment porté sur les deux catégories de métadonnées liées aux images numérisées: les métadonnées Exif et les métadonnées IPTC.
IPTC
Ce type de métadonnées sert en premier lieu à identifier l’institution et à gérer les droits d’utilisation. Les noms du pays, du canton et de l’institution qui met à disposition ses images et qui conserve les originaux est indispensable pour leur identification. En revanche, s’il est prévu de mettre à disposition les images pendant une longue durée, les métadonnées susceptibles de changement sont peu intéressantes à compléter (par exemple l’adresse web ou email de l’institution). Une recherche sur le nom d’une institution permet de retrouver facilement ces informations susceptibles de changer régulièrement.
On constatera qu’aucune cote ou identifiant unique ne figure par parmi ces champs. Dans le cas de ce projet, cette information apparaît uniquement dans le nom du fichier. Ce n’est peut-être pas une solution idéale, mais intégrer la cote dans les métadonnées IPTC aurait nécessité un post-traitement qui devait être évité dans le cadre de ce projet.
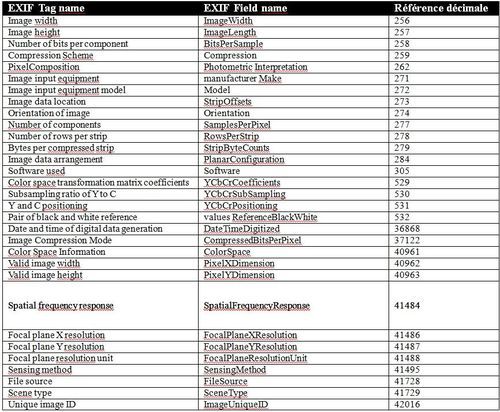
EXIF
Le cas des métadonnées EXIF est un peu particulier. Ces métadonnées techniques relèvent en définitive plus de la conservation à long terme que de la diffusion. Toutefois, tous les appareils d’imagerie numérique produisent ces métadonnées. Faut-il les conserver ou les supprimer ? Leur taille étant négligeable en regard du poids des images, il a été décidé de les garder. Mais quelles métadonnées EXIF sélectionner parmi le vaste panel proposé par ce modèle ? Quelques contacts menés auprès de diverses institutions ont démontrés des pratiques assez aléatoires. Généralement, on se contente des réglages installés par défaut sur la machine. La question est d’autant plus difficile que l’on entre dans un domaine technique qui devient vite pointu et avec lequel les photographes ont souvent plus d’affinités que les archivistes.
Pour répondre à cette question, la norme américaine Z39.87 “Data Dictionnary – Technical Metatata for Still Image”, qui offre un jeu de métadonnées pour la gestion tout au long du cycle de vie des images “pixellisées” (bitmap ou raster), a servi de point de départ. Cette norme n’est d’ailleurs pas sans lien avec le modèle PREMIS, ce qui est intéressant dans le cas d’une éventuelle réutilisation de ces métadonnées internes. A partir de là, une table d’équivalence entre la version “trial 2002” de cette norme et les spécifications EXIF 2.2 a été utilisée pour identifier les champs permettant de répondre aux exigences Mandatory (M), Mandatory if Applicable (MA) ou Recommend ® de Z.39.87. Attention, il n’existe pas systématiquement un champ EXIF pour répondre aux exigences de la norme. Certains champs retenus peuvent ainsi ne pas être renseignés. La norme n’est donc pas entièrement respectée, mais on s’en rapproche le plus possible. A partir de là, un jeu de métadonnées techniques minimales a été choisi à l’aide des champs EXIF.
Métadonnées retenues:
- Métadonnées images retenues par les archives de la Ville de Genève
XMP
Un des principaux choix à effectuer est le standard à utiliser pour intégrer les métadonnées (IPTC, Exif ou XMP). XMP a été retenu pour les avantages que présente ce format (basé sur XML et RDF, extensible, standard récent) mais également car c’est le seul des trois standards qui permet d’intégrer des métadonnées dans des fichiers qui ne sont pas des images, notamment des PDF. Dans le cadre d’un projet de numérisation, XMP rend possible l’utilisation des mêmes éléments de métadonnées quel que soit le type de fichier produit (JPG et PDF par exemple).
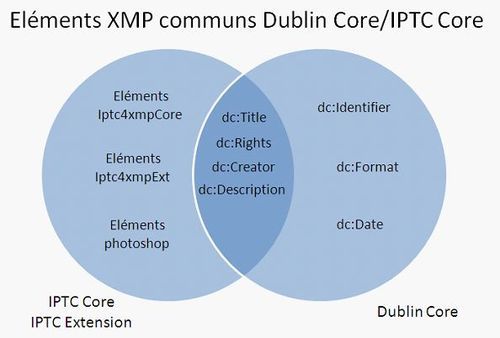
Dublin Core
A l’intérieur d’XMP les métadonnées peuvent être exprimées à l’aide de différents schémas (IPTC Core, Dublin Core, schéma photoshop etc.). Il est donc nécessaire de faire des choix parmi ces standards. Un nombre limité d’éléments Dublin Core a été retenu car ils semblaient bien répondre aux objectifs de base (identifier les images et donner le statut juridique).
Métadonnées retenues:

Le jeu de métadonnées Dublin Core est assez central dans XMP, en effet les informations de description élémentaires sont souvent signalées à l’aide de ce schéma. IPTC Core s’appuie également sur certains éléments Dublin Core. Ainsi, plutôt que de créer un nouvel élément ad hoc pour le titre d’une photographie, IPTC Core recommande l’utilisation de l’élément « titre » de Dublin Core (dc:Title). Puisqu’ils sont fréquemment utilisés, ces éléments Dublin Core sont plutôt bien reconnus et ils ont d’autant plus de chances d’être lus par les différents logiciels de visualisation d’images. Les nombreux logiciels qui reconnaissent les métadonnées IPTC Core seront donc capables d’afficher (au minimum) les éléments communs à Dublin Core et IPTC Core (voir ci-dessous).
Références