Par Xavier Ciana, Emmanuel Ducry et Anouk Dunant Gonzenbach
Lors d’un projet de numérisation de documents, il est nécessaire de se pencher sur la question des métadonnées images pour des raisons de gestion documentaire, de droits d’accès, de recherche, d’identification du document, etc.
La problématique abordée ici concerne la numérisation de documents ou registres patrimoniaux à des fins de diffusion. C’est un point qu’il vaut mieux en effet aborder dès le début d’un projet de numérisation. Dans le cas présent, il s’agit d’un projet qui a débuté en 2006 et à cette époque, nous n’avions pas imaginé normaliser ces métadonnées. Ce besoin s’est ensuite fait ressentir et c’est pourquoi nous proposons aujourd’hui cette réflexion.
En Suisse romande, il n’y a pas d’harmonisation des pratiques concernant les métadonnées liées aux images numérisées diffusées en ligne par des institutions d’archives. De plus, on constate que la littérature professionnelle sur le sujet du point de vue archivistique n’est pas complètement aboutie.
La question de ce type de métadonnées sera abordée en 4 billets:
1. Panorama des principaux standards en matière de métadonnées intégrées aux documents numérisés (ci-dessous)
2. Liste des métadonnées retenues par deux institutions publiques genevoises dans le cadre de leurs projets de numérisation
3. Le choix du droit d’utilisation des images
4. Retour d’expérience par rapport à ces choix
LES STANDARDS DES METADONNEES
Les trois standards majeurs en matière de métadonnées intégrée aux images sont :
IPTC-IIM
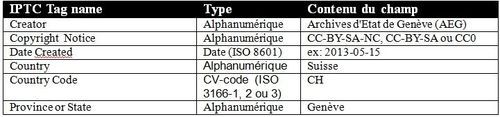
L’IPTC (International Press Telecommunications Council) développe au début des années 1990 l’Information Interchange Model (IIM), qui est une structure et un jeu d’attributs de métadonnées applicable à des fichiers texte, des images et d’autres types de média. En ce qui concerne les images, les attributs prévus par le modèle IPTC-IIM comportent par exemple : le créateur, le titre, la date, des informations géographiques (pays, région, ville) ou des éléments de description (mots-clés, légende). Au milieu des années 1990, les logiciels d’Adobe – notamment Photoshop – ont permis d’intégrer ces éléments directement dans les fichiers images. Cette façon de faire a dès lors connu un large succès, de nombreuses images ont été « augmentées » de métadonnées et aujourd’hui encore, beaucoup de logiciels de visualisation ou de retouche photographique permettent d’afficher et de modifier ces informations. Par commodité de langage, celles-ci sont généralement appelées « métadonnées IPTC » ou « en-têtes IPTC / IPTC headers ».
A l’heure actuelle, cette manière d’intégrer les attributs IPTC-IIM directement dans les images est en passe de devenir obsolète, en effet, les auteurs du modèle IPTC-IIM recommandent maintenant d’utiliser le standard XMP pour inclure ces attributs dans des fichiers.
EXIF
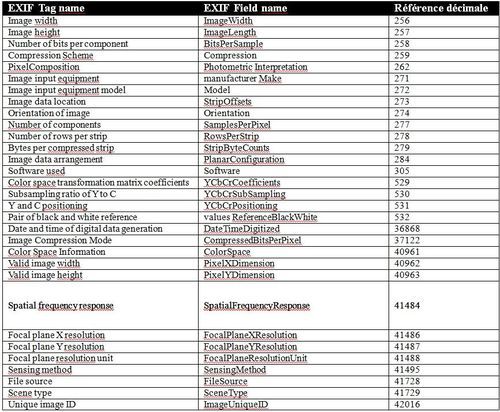
Etablie à l’origine par le Japan Electronic Industry Development Association (JEIDA), l’Exif (Exchangeable image file format) est une spécification de formats de fichiers pour les images et sons produits par les appareils photographiques numériques. Cette spécification repose sur des formats existants (tels que JPEG et TIFF pour les images ou RIFF WAV pour les fichiers audio), et y ajoute des balises de métadonnées. Les métadonnées Exif sont typiquement générées automatiquement lors de la création d’une image, c’est-à-dire par l’appareil photo au moment de la prise de vue. La très grande majorité des métadonnées Exif sont techniques, il s’agit d’éléments tel que la taille de l’image, la résolution, la compression ainsi que des données concernant la prise de vue : la date, le temps de pose, la distance focale, l’utilisation d’un flash, ou encore la position GPS de l’appareil. Le grand avantage des métadonnées Exif est l’automatisation : la plupart des appareils photographiques numériques (notamment les smartphones) créent des données Exif dans les images, même sans aucune intervention de l’utilisateur. De plus, les métadonnées Exif sont largement reconnues et peuvent être lues et affichées par un grand nombre de logiciels de traitement d’images et ceux-ci conservent généralement les données Exif lors des modifications successives des fichiers. Enfin certains sites web exploitent également de manière automatique les métadonnées Exif présentes dans les images, notamment les coordonnées GPS.
XMP
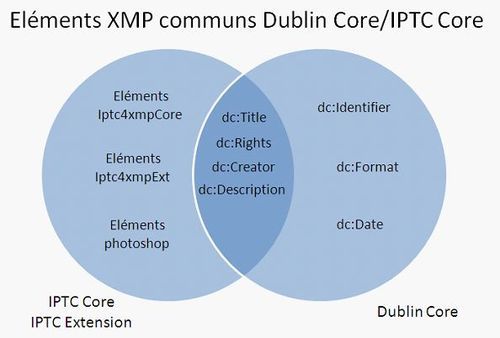
En 2001, Adobe introduit l’ “Extensible Metadata Platform” (XMP), un standard basé sur XML et RDF, qui permet d’intégrer des métadonnées dans plusieurs formats de fichiers (TIFF, JPEG, JPEG 2000, PDF, PNG, HTML, PSD etc.). XMP est extensible et peut donc accueillir n’importe quel type de métadonnées du moment que celles-ci sont exprimées en XML. Dès l’origine, XMP incorpore un certain nombre de standards de métadonnées, un des plus importants étant certainement Dublin Core, qui permet d’accueil des métadonnées élémentaires tel qu’auteur, titre, identifiant, date ou encore des informations sur les droits d’auteurs du document. « IPTC Core » est un autre des schémas majeurs inclus dans XMP, il permet d’utiliser les attributs du modèle ITPC-IMM (décrit ci-dessus) à l’intérieur d’XMP. Le schéma « IPTC Core » fait donc d’XMP le successeur officiel aux métadonnées IPTC.
Un dernier exemple de schéma pouvant être intégré à XMP est VRACore, un standard destiné à la description des objets ou œuvres d’arts représentés dans des photographies. VRACore n’est pas centré sur le fichier image, mais sur l’œuvre originale. Ce standard permet notamment d’en décrire l’auteur, la taille, les matériaux ou techniques de création, ainsi que signaler le musée ou l’institution qui conserve l’objet original.
Le champ couvert par les métadonnées XMP est donc très large et comporte aussi bien des informations de description, notamment via Dublin Core, que des données techniques ou encore des éléments de gestion de droits d’auteur ou de workflow.
L’intégration de métadonnées à des images grâce à XMP est intéressante à plusieurs titres : comme les données sont en XML/RDF elles peuvent être exploitées à l’aide d’outils standards. En outre de plus en plus de logiciels récents (notamment Windows 7) sont capables d’afficher et d’exploiter les métadonnées XMP. Enfin, si une institution à des besoins spécifiques, il lui est possible d’intégrer ses propres modèles de métadonnées dans XMP.
Cohabitation des standards
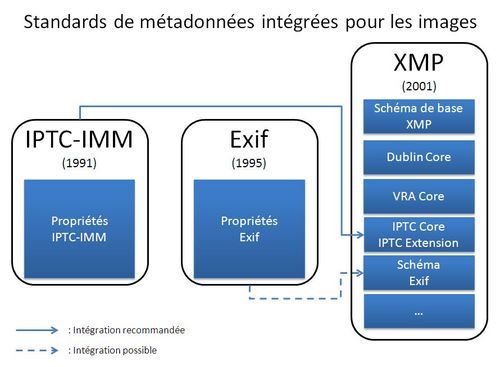
Techniquement, des éléments provenant des trois standards (IPTC-IIM, Exif et XMP) peuvent figurer dans un même fichier sans aucun problème.
Au niveau du contenu des métadonnées, les choses ne sont pas aussi simples : en effet certaines informations peuvent être répétées dans les trois standards, notamment des éléments de base tels que le créateur d’une image, sa date ou encore son droit d’utilisation. Si plusieurs standards sont utilisés simultanément, il est alors nécessaire d’assurer la cohérence des contenus afin d’éviter les disparités (par exemple un même fichier avec une date de création dans Exif et une date différente dans XMP). Le Metadata Working Group, une coalition réunissant notamment Adobe, Apple et Microsoft, a émis des recommandations afin d’assurer la cohérence et la préservation des métadonnées lors de l’utilisation simultanée de plusieurs standards.
De multiples scénarios de cohabitation sont possibles : un même fichier peut par exemple contenir des métadonnées techniques issues du scanner dans Exif tandis que les métadonnées de description et celles relatives au droit d’auteur sont exprimées dans XMP. Comme on peut le constater dans le schéma ci-dessous, il est également possible de regrouper l’ensemble des données ITPC ou Exif dans XMP.
CC-BY
Comment lire les métadonnées ?
Les métadonnées peuvent être à ajoutées à des images dans un but interne à une institution (description, processus de travail etc.), ou dans un but externe (enrichir les informations lors la diffusion). Quelles que soient les raisons initiales qui justifient l’intégration de ces informations à des fichiers images, il est évidemment souhaitable que celles-ci puissent être lues par les plus grand nombre de personnes qui vont consulter ou réutiliser ces images. Cette lecture dépend des logiciels utilisés pour visualiser les images. Si la majorité des logiciels de gestion et traitement de photographies sont capables de lire et de modifier les métadonnées intégrées, ce n’est pas le cas de tous les systèmes d’exploitation et logiciels généralistes. Windows XP utilise son propre système de métadonnées et de commentaires ad hoc appelé “Alternate Data Streams (ADS)” et peut uniquement lire un nombre restreints d’éléments Exif. Pour un utilisateur de Windows XP, la quasi-totalité des métadonnées intégrées dans une image seront donc invisibles. Le support pour lire les métadonnées « de base » (auteur, titre, date, droits, etc.) est meilleur dans les systèmes d’exploitation plus récents. Dans Windows 7, certains éléments des métadonnées issus des trois standards sont directement affichés dans l’explorateur ou figurent dans l’onglet « détail » de chaque fichier. Windows 7 est également capable de faire des recherches dans les métadonnées intégrées. Mac OS X permet lui aussi (dès la version 10.6) de rechercher dans les métadonnées et le logiciel « Aperçu » (utilisé par défaut pour ouvrir les images) affiche des éléments provenant des trois standards.
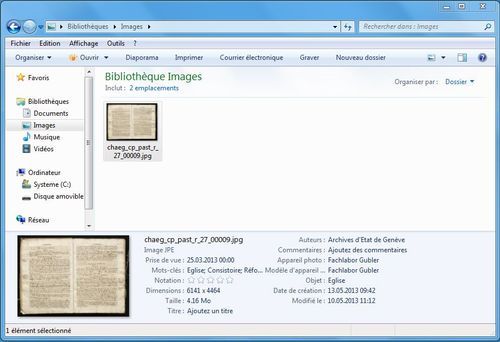
Eléments de métadonnées affichés par l’explorateur Windows 7.
Le nom affiché ci-dessus sous « Auteurs » a été intégré à l’image grâce au standard XMP, dans l’élément Dublin Core « creator ».
Références