par Anouk Dunant Gonzenbach
Il y a plusieurs mois, le thème de la médiation numérique en bibliothèque était à l’honneur des discussions des forums professionnels et des réseaux sociaux. Qu’en est-il pour les institutions d’archives ? En creusant la question, il me semble que non seulement nous sommes largement concernés par cette question, mais qu’il relève carrément de notre devoir de mettre en place ce genre de chose !
Google permet-il de faire une recherche historique? Est-il encore nécessaire de se rendre aux Archives? Tous les documents des Archives sont-ils accessibles en ligne? Comment se repérer dans un inventaire d’archives? Quels documents sont conservés aux Archives?
Même si on voulait ne s’adresser qu’au monde très pointu des chercheurs expérimentés (mais on est d’accord, hein, ce n’est pas ce que l’on veut) déjà on remarquerait qu’il y aurait moyen de les accompagner sur les outils numériques mieux qu’on ne le fait actuellement.
Donc allons-y, proposons de la médiation numérique. Objectif de l’année (flashback sur janvier 2013). Comment commencer ? Il faut déjà identifier le public-cible. Imaginer un module destiné aux étudiants en histoire dont le séminaire se déroule aux Archives, et un module « public élargi » à l’intention des personnes fréquentant la salle de lecture, pour commencer. Les objectifs ? Présentation des différentes possibilités de recherche, aide pour la préparation d’une session de travail aux archives et pour se repérer dans les différentes institutions d’archives, recherche dans la base de données et consultation optimale des documents numérisés. Nous avons commencé par quelques réflexions sur le module destiné aux étudiants. Par où commencer, ou plutôt sur quelles connaissances préalables des étudiants peut-on s’appuyer ? Nous avons toujours tendance à penser, puisque nous sommes dans notre institution jusqu’au cou, que tout est clair pour tout le monde. Grave erreur à mon avis. On s’y met donc à plusieurs. Le module voit le jour.
Une première partie est consacrée à la présentation de l’institution, brièvement à son histoire, aux missions de l’archiviste ainsi qu’aux principales sources conservées. Confirmation, ce n’était pas clair dès le départ pour tout le monde.
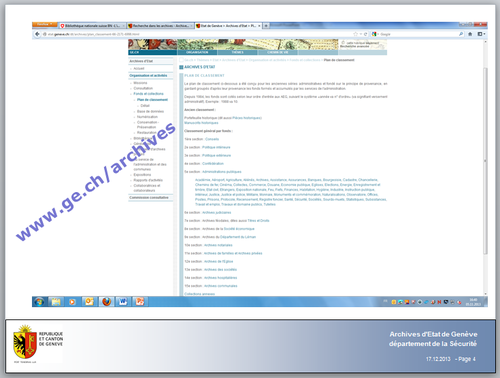
Passons aux outils numériques, mais on commence simplement en présentant le site web institutionnel et ses ressources (par exemple les news, les horaires d’ouverture des différents dépôts, un état général des fonds statique). Je le précise tout de suite, on n’est pas encore sur Facebook, les voies de l’administration sont parfois impénétrables.
Puis vient la présentation de la base de données de descriptions de documents (les inventaires, en fait). Nous expliquons que les inventaires sont saisis sur notre base depuis 1986 et qu’il y a assez peu de saisie rétroactive des inventaires papier (manuscrits et tapuscrits). Ainsi, on ne peut pas partir du principe que tous les documents sont décrits dans la base de données. De plus, cette base de données, au départ uniquement utilisée en interne, a été ouverte au public en 2006 ; les descriptions contenant des données personnelles ne sont pas accessibles au public. Il est important aussi de préciser que ce n’est pas parce qu’une description se trouve sur internet que le document ou le dossier est forcément consultable (il faut donc expliquer les bases légales relatives à la consultation des documents).
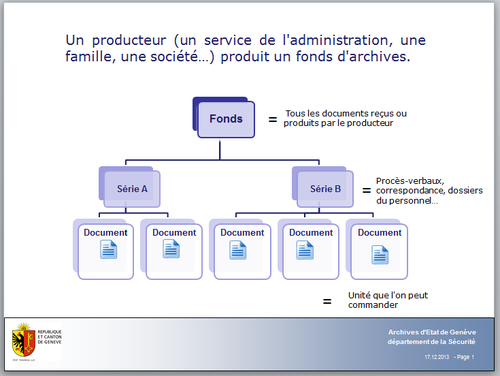
Ces points posés, on peut maintenant faire une démonstration de la manière d’effectuer une recherche. Et là, difficulté, comment éviter de parler du concept de fonds d’archives ? A ce stade, pas possible de reculer, il faut simplifier le propos et définir le fonds. Ce qui en l’état actuel de nos bases de données est évidement important pour le lecteur ou l’étudiant qui voudra approfondir une recherche (notre base de données permet la recherche par fonds, par thème ou mot-clé et par cote).
Nous expliquons également comment fonctionne la réservation en ligne d’un document (il est possible de le faire sortir en salle de lecture pour un jour précis mais évidemment pas de l’emprunter).
Ensuite, nous montrons comment consulter les images numérisées en précisant les choix et priorités de numérisation des séries.

Je passe les autres détails, mais il y a certains points clés sur lesquels nous avons insisté. Je pense que ces messages sont très importants à faire passer :
- Ce n’est pas parce qu’une recherche dans un base de donnée d’archives ne donne aucun résultat qu’il n’y a pas de documents concernant cette recherche.
- Ce qui est sur internet est un sous-ensemble de la base de données métiers.
- Ce n’est pas parce que ce n’est pas sur internet que ça n’existe pas.
- Seule une petite proportion de nos documents est numérisée.
- Le contenu des images numérisées ne peut pas être recherché à travers Google (pas – encore- d’OCR sur les images numérisées).
Un retour ? les étudiants prennent même des notes ! Et relèvent l’URL du site institutionnel inscrit en tout gros sur une slide (il faut partir des basiques, c’est décidément certain).
Je pense qu’il y a plusieurs suites à donner à l’évolution de ce genre de projet. Tout d’abord, continuer à faire de la médiation numérique pour le public qui fréquente la salle de lecture. Ensuite faudrait-il peut-être aller à l’Université plus systématiquement dans des séminaires d’histoire, utilisateurs ou non notre institution d’archives. Utiliser et promouvoir le compas d’Infoclio dans le domaine des compétences informationnelles.
Il y a également la question de la médiation numérique en ligne. Là, nous sommes en train de préparer une ébullition de méninges à ce sujet dans la région des archivistes du grand Genève (!), à suivre.
Et puis la question de l’ouverture des archives à d’autres publics. Nos outils sont orientés métier, et quand il s’agit d’expliquer dans les détails le fonctionnement de notre base de données on se rend bien compte que le contenu n’est pas accessible facilement. Nous adapter ? Essentiel.
Et vous, des expériences de médiation numérique en archives ?